BERT and GPT
简介
Transformer
http://nlp.seas.harvard.edu/2018/04/03/attention.html
![]()
BERT
https://www.bilibili.com/video/av54806580
如何训练BERT
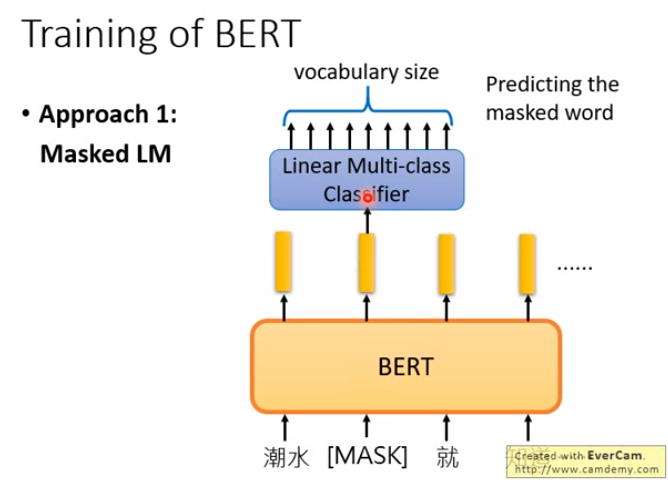
方法一:Masked LM:对一句话中的随机单词进行遮挡,通过剩下的部分来预测这个单词。
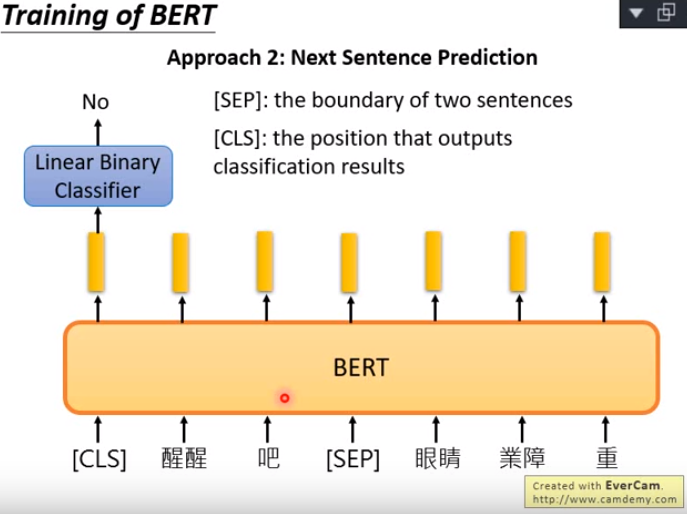
方法二:Next Sentence Prediction,将两个句子用一个特殊的token [SEP]串接起来,使用输出开始的位置的向量添加线性分类器得到是否是两个连续句子的判断。
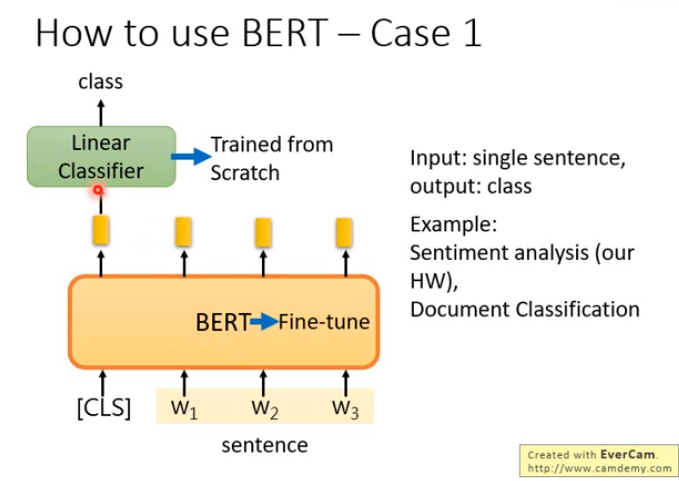
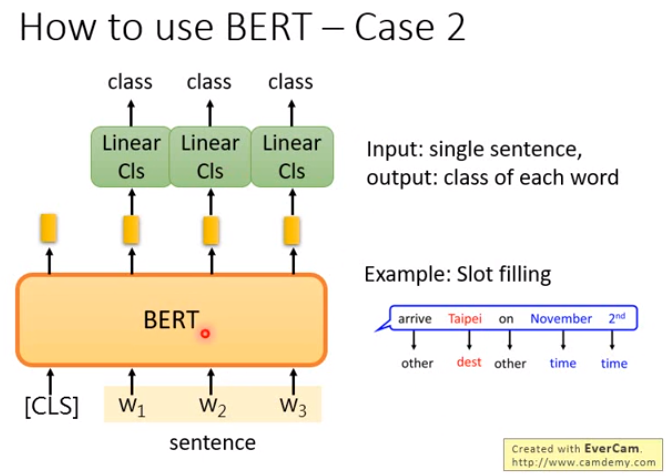
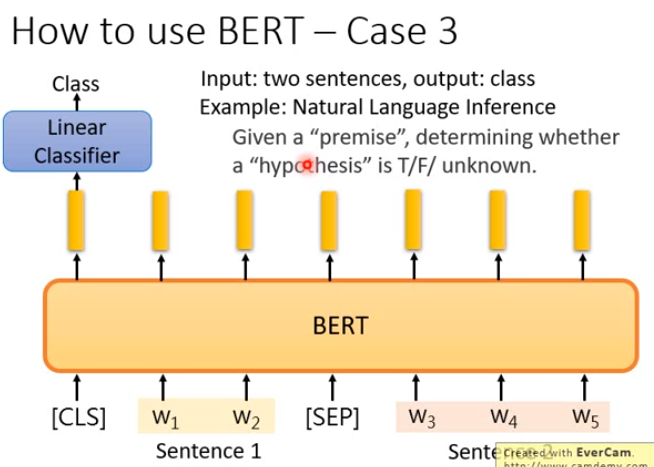
BERT的使用场合
| 序号 | 输入 | 输出 | 例子 |
|---|---|---|---|
| 1 | 单个语句 | 一个类别 | 情感分类,文档分类 |
| 2 | 单个语句 | 每个单词的类别 | Slot filling |
| 3 | 两个语句 | 一个类别 | Natural Language Inference |
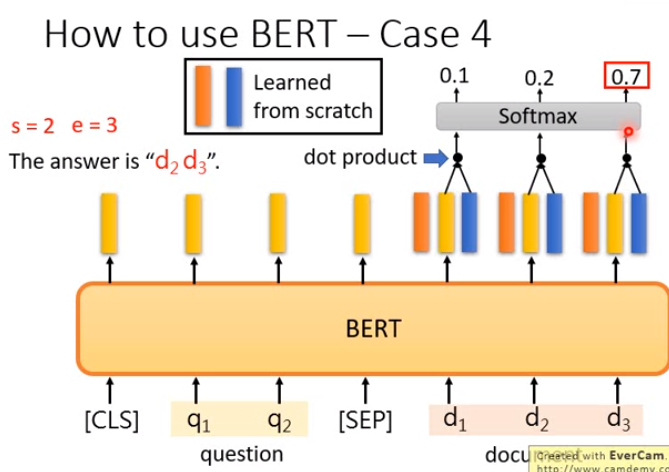
| 4 | 两个语句 | 一个起始位置,一个结束位置 | Extraction-based Question Answering (QA) e.g. SQuAD |
GPT
实践建议
Pytorch transformers library: https://pytorch.org/hub/huggingface_pytorch-transformers/
数据输入格式技巧:
- 对于语句分类任务而言:
- 对于每个句子的开始处和结束处加入特殊的token。
[SEP]: 在每一个句子的结尾加入一个这样的token。[CLS]: 对于分类任务而言,我们需要在每一句话的开始加入该token。
- 使用填充或者截断使得输入的句子长度一致。
- 使用attention mask来编码位置,并区分句子中填充的位置和包含内容的位置。
- 对于每个句子的开始处和结束处加入特殊的token。
参考
TODO