风格迁移算法
风格迁移算法能够改变图像的风格,同时保持图像的内容不变,例如添加绘画名家的绘图风格到普通相片,转变风景的季节和天气,手绘和真实图像的转换等。本博客会介绍目前常用的风格迁移算法原理以用作参考和研究。
前言
现代神经网络模型允许我们改变一个图像的“风格”到另一个“风格”,同时保持图像的内容不变。例如将一张正常拍摄的人物肖像转变风格为带有梵高,莫奈等名家绘画风格的图像,将一张夏日的风景图像转变为冬季下雪的照片图像,将一张手绘风格的草图转换为具有真实感的照片等等,这些应用的原理都是使用风格迁移算法。风格迁移算法得益于卷积神经网络强大的特征提取和图像生成能力。本博客会介绍目前常用的风格迁移算法原理以用作参考和研究。
基于优化的方法
A Learned representation for artistic style
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
根据之前的工作(A Learned representation for artistic style),通过调整图像feature的均值和方差,保持卷积核的参数不变即可以改变图片的style。所以通过直接统计style图片中的均值和方差即可以对content图像的feature进行normalize,这被称为AdaIN(Adaptive instance normalization):
\[AdaIN(x, y) = \sigma(y) (\frac{x-\mu(y)}{\sigma(x)}) + \mu(y)\]该工作的网络使用了一个encoder-decoder结构:

它使用一个content图片\(c\)和style图片\(s\)图片作为输入,通过一个fixed的VGG网络作为encoder将两张图片映射到特征空间,然后通过AdaIN层将两个feature map的均值和方差进行对齐,得到目标feature map \(t\):
\[t = AdaIN(f(c), f(s))\]然后一个可学习的decoder用来将feature map映射到图片空间得到风格化的图片\(T(c, s)\):
\[T(c, s) = g(t)\]decoder的结构和encoder类似,不过将所有的pooling层替换为了nearest up-sampling层,同时避免使用BN或者IN来避免对生成图像的风格再改变(参考原文讨论)。在encoder和decoder中都使用reflection padding来避免border artifacts。该方法可以以15 FPS的速度在Pascal Titan X机器上生成512x512的图像,并且可以适应任何风格。
Controlling Perceptual Factors in Neural Style Transfer
TODO
Deep Photo Style Transfer
TODO
基于模型的方法
Pix2Pix
图像翻译(Image Translation)的目标是将图像从一个表达转移到到另一个表达,就像翻译时候由英语到法语的逐词翻译一样,图像翻译逐像素对图像进行转换表达。Pix2Pix 是第一个能完成不同图像翻译任务的框架。它的原理是使用一个Conditional GAN来生成图像,使用待翻译的图像作为生成图像的条件,使用GAN的生成器来生成一个接近真实照片的图像。因此该框架的损失函数设计是GAN的损失函数结合一个传统的损失函数L1 Loss,因为实验发现这样可以取得更理想的结果。
在网络结构设计方面该工作提出了几个方法来来提高图像翻译的结果:
- 在GAN的生成器上,使用U-net形式的结构,添加了跨层连接。这是因为在编码-解码的网络结构中,跨层连接可以让 low-level 信息直接传递到输出位置,从而减少信息在编码过程中的损失,这对于保留图像细节有帮助;
- 使用PatchGAN形式的Discriminator。PatchGAN会将输入图片downsample成 \(N \times N\) 个patch,然后通过对每个patch的分数取平均来判断图片的真伪。这种做法和L1 loss相互补充。L1 loss部分约束低频部分的正确性,而PatchGAN约束高频部分(纹理,风格)的正确性,将模型注意力限制到局部的patch上。
- 在生成图像阶段,生成器输入的噪声不是来自一个单独的变量,而是来自generator中的前3层中的dropout操作。
Cycle GAN
不像Pix2Pix,CycleGAN可以训练这个风格转变,而且不需要两个domain的一对一匹配的数据来训练。取而代之的是使用一个两步的方法将source domain的映射到target domain,然后再将它映射会source domain。Generator用来将source domain的图像映射到target domain,而discriminitor与generator对抗训练来提高生成的图片的质量。
Cycle-Consistent:
为了regularize 模型,作者提出了cycle-consistent约束:如果我们从源分布变换到目标分布然后再变换回来,我们应该得到我们源分布的采样。
CycleGAN的整体框架如下:
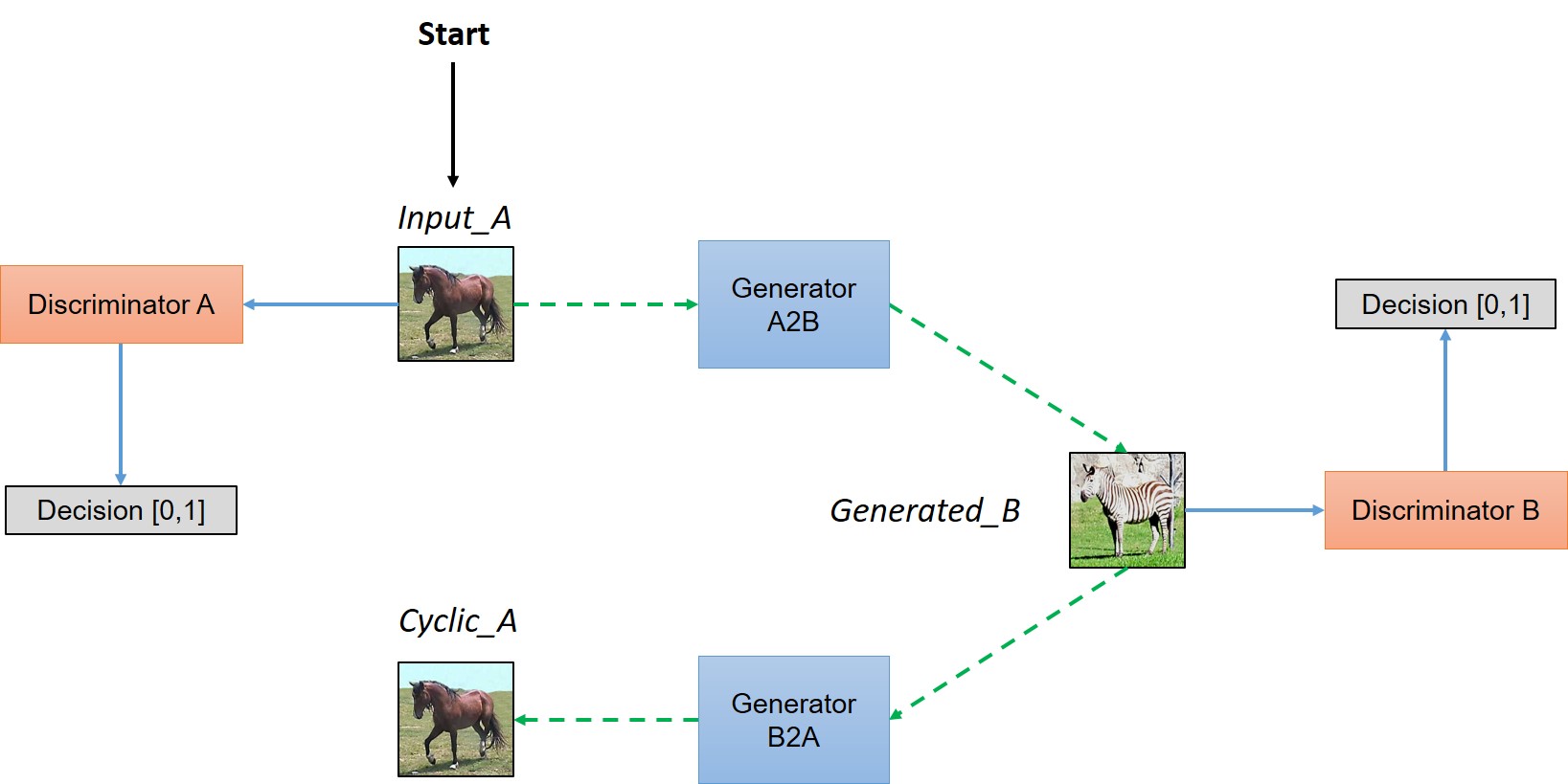
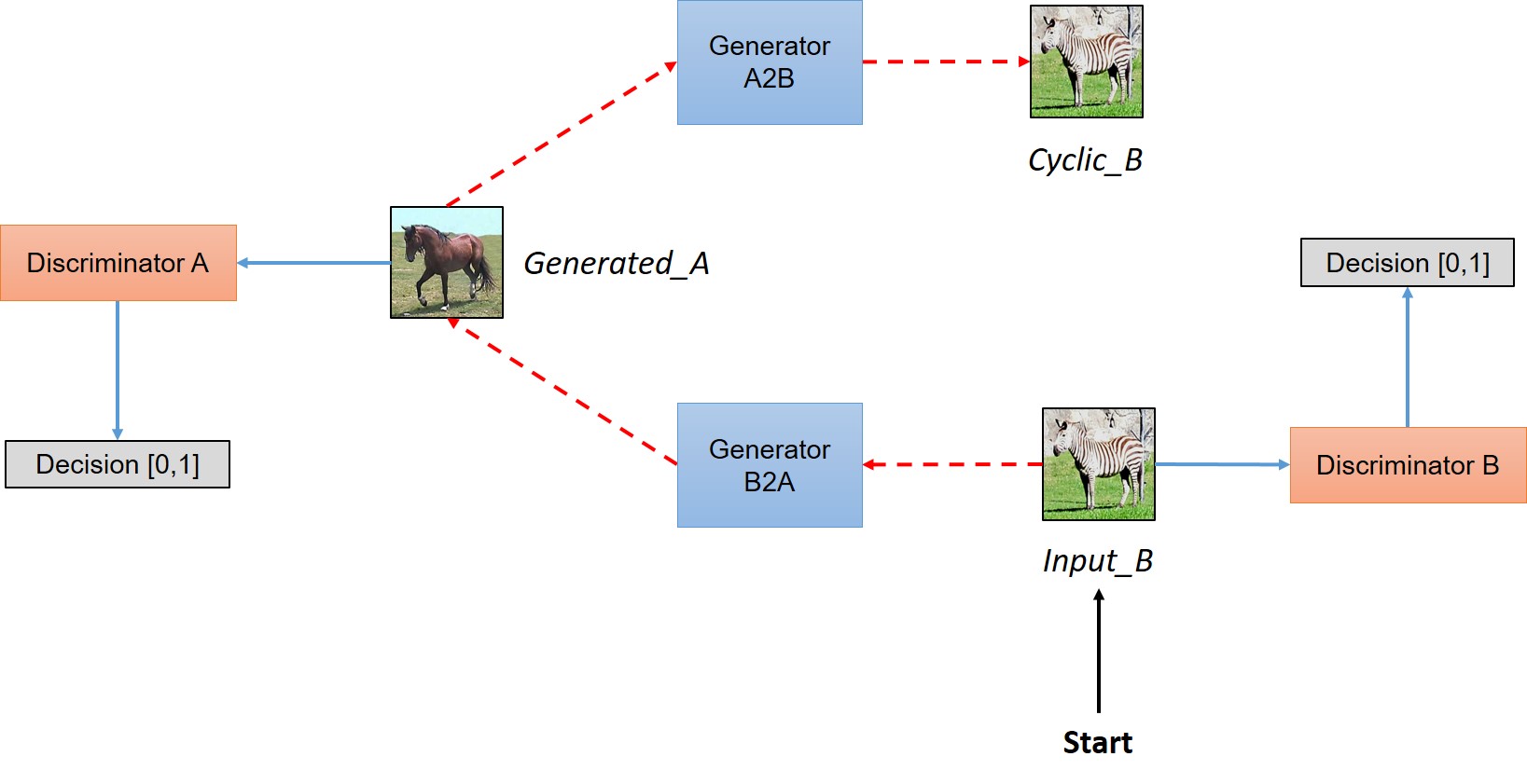
在CycleGAN中,我们所训练的数据不是pair而是一个domain \(D_A\) 到另一个domain \(D_B\), 当我们把一张图像\(Img_A\)从source domain转换到target domain的时候,在target domain没有一个真值\(Gen_B\)。但是,由于转换后的图像和原来的图像必然后sharing features,所以必然有一个映射将转换后的图像变为原来的图像\(Img_A\),这样才能训练一个有意义的mapping。
简单来说,CycleGAN模型包含两个生成器 \(Generator_{A \to B}\), \(Generator_{B \to A}\)。在训练阶段,当给模型输入一个\(D_A\)的图像\(Img_A\),\(Generator_{A \to B}\) 将其转化为\(D_B\)的图像\(Gen_B\)。然后\(Generator_{B \to A}\)再将\(Gen_B\)转化到\(D_A\),即\(Cyclic_A\)。我们希望训练模型使得\(Cyclic_A\)和\(Img_A\)的差异很小(类似与autoencoder),同时完成生成器和判别器达到 Nash equilibrium,即生成器能够生成target domain同样的分布。
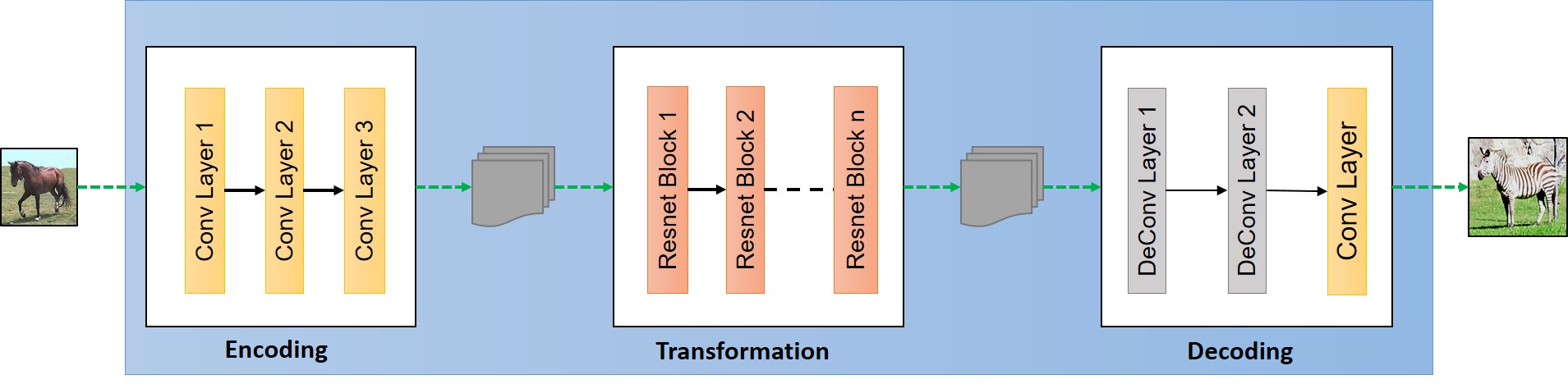
具体来说,生成器可以采用如下结构:
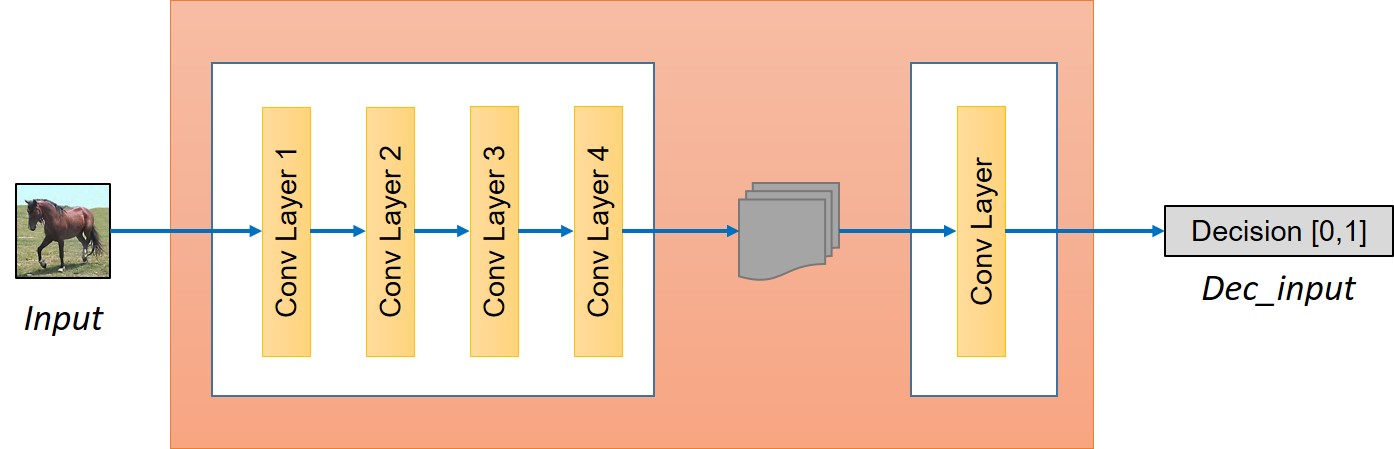
判别器可以使用如下结构:
损失函数的设计依照下面四个步骤:
- 判别器成功判断所有original images为0。
- 判别器成功判断所有generated images为1。
- 生成器成功生成被判别为0的generated images。
- 生成器生成的图像满足cyclic consistency。
MIXGAN: Learning Concepts from Different Domains for Mixture Generation
有没有方法让GAN从一个domain中学习content,另一个domain中学习style,然后generate出融合后的样本?该工作提供了一个这样的思路。
它的整体框架如下, mixture generator \(G\) 包含两个部分 content decoder \(G_c\) 和 mixture decoder \(G_m\)。content decoder使用一个AAE将内容图片encode到一个高斯分布。然后mixture decoder融合content decoder的输出,并将生成的图片和style 图片做判别。判别器部分使用PatchGAN来学习style部分信息。
