使用 Python 和 Selenium 爬取 Science 论文
本博客会介绍如何使用 Python 和 Selenium 自动操作浏览器批量下载 Science 网站下某一个主题的论文。实现这个功能可以使用 Selenium 进行无头浏览器访问DOM元素,控制浏览器窗口,设置浏览器等待的时间来模拟正常浏览器的操作。
简介
Selenium 能够自动化操作预先定义的浏览器,从而完成自动化测试或者数据爬取工作。你可以使用 selenium 的函数来完成和浏览器的操作和访问浏览器的数据和变化。 Selenium 可以使用的浏览器驱动包括 Firefox,Chrome,Edge,Safari。
你可以在 selenium 的函数工作的过程中看到浏览器的界面,或者,将浏览器以无头模式运行来进行HTTP请求。无头浏览器和普通浏览器的功能一样,除了不包含可是的界面,但是仍然可以做出请求,渲染HTML,保持session信息,进行JavaScript的异步请求。
本博客会实现一个批量下载 Science 网站下某一个主题的论文的功能来介绍 Python 和 Selenium 的使用。
软件安装
selenium
使用 pip 安装 selenium:
pip install selenium
然后,你还需要安装浏览器的驱动来提供操作的接口。
Chrome
你可以这里下载到Chrome的驱动。如果使用的是linux系统,下载后将它放置到~/.local/bin来帮助 selenium 找到它。
Firefox
使用firefox进行自动化操作需要的的驱动为geckodriver,下载它的可执行文件之后,将它放置到系统环境变量包含的路径下。
Ubuntu22.04上运行代码可能会出现profile not accessible错误,这是由于使用snap安装firefox,profile的路径由以往的~/.mozilla/firefox/变更到了~/snap/firefox/common/.mozilla/firefox/,geckodriver不知道profile路径的变更,需要手动告诉它新的profile路径。
from selenium import webdriver
options = webdriver.FirefoxOptions()
options.add_argument('--profile')
profile_path = "/home/USERNAME/snap/firefox/common/.mozilla/firefox/hzepd0mp.selenium"
options.add_argument(profile_path)
browser = webdriver.Firefox(options=options)
browser.get('http://selenium.dev')
其中的profile路径可以通过在firefox浏览器输入about:profiles查看得到。
Edge
Edge的驱动可以在这里下载得到。
使用 Selenium 访问 DOM 元素
你可以使用 python 代码导入 selenium 来访问网站:
from selenium import webdriver
driver = webdriver.Chrome()
url="https://search.sciencemag.org/?searchTerm=fiber&order=tfidf&limit=textFields&pageSize=100&startDate=2019-01-01&endDate=2019-12-31&articleTypes=Research%20and%20reviews&source=sciencemag%7CScience"
driver.get(url)
# driver.close()
这段代码首先导入了 webdriver 模块,然后创建了 driver 对象来操作 Chrome 浏览器,由于之前将驱动放到 ~/.local/bin 路径,所以 selenium 能够找到它。之后使用 driver 访问指定的 url,这个 url 是 science 网站论文搜索的地址,其中设置了参数,指定了搜索的主题是 fiber, 时间范围是 2019年1月1日 到 2019年12月31日,论文类型为 Research and Review。执行成功后,你可以看到一个浏览器被打开并显示如下界面:
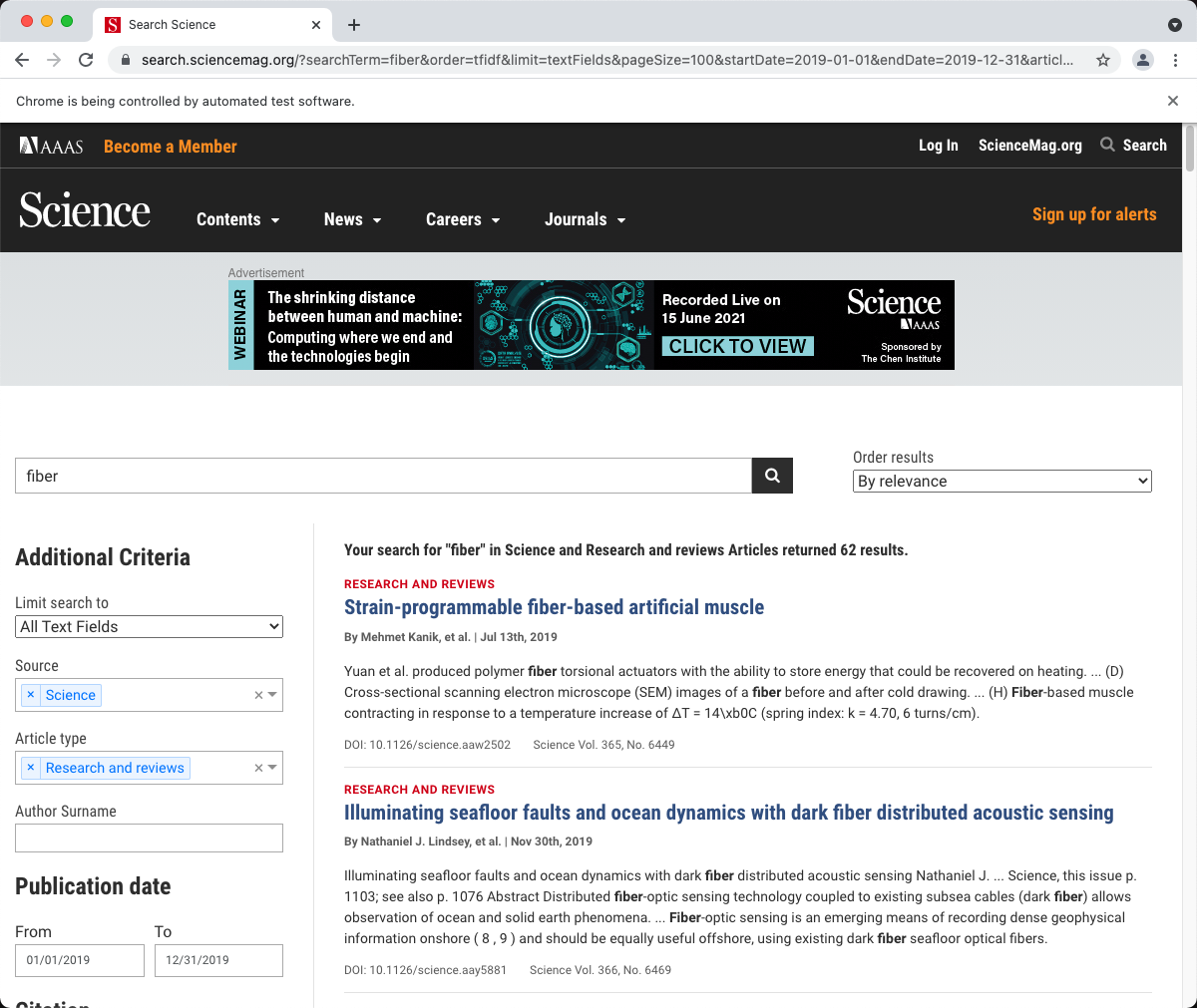
selenium 会一直保持对driver的操作连接直到driver.close()命令。如果你是使用 python 解释器运行的上面的指令,或是是使用python -i script.py来在脚本文件运行完成后保持解释器,那么就可以继续输入代码来操作当前活动的浏览器。
当 selenium 控制浏览器打开网页加载完成后,就可以访问其中的内容或者进行下一步操作。比如使用print(driver.title)可以打印处网页的标题。
接下来会模拟鼠标点击网页上一个第一个论文链接的操作。selenium 支持不同的方法来定位到HTML元素,包括:
- xpath:
find_element_by_xpath() - css id:
find_element_by_id() - css class:
find_element_by_class_name()
这里使用xpath来定位到第一个论文连接,我们可以使用chrome 开发工具来用鼠标选择到这个链接:
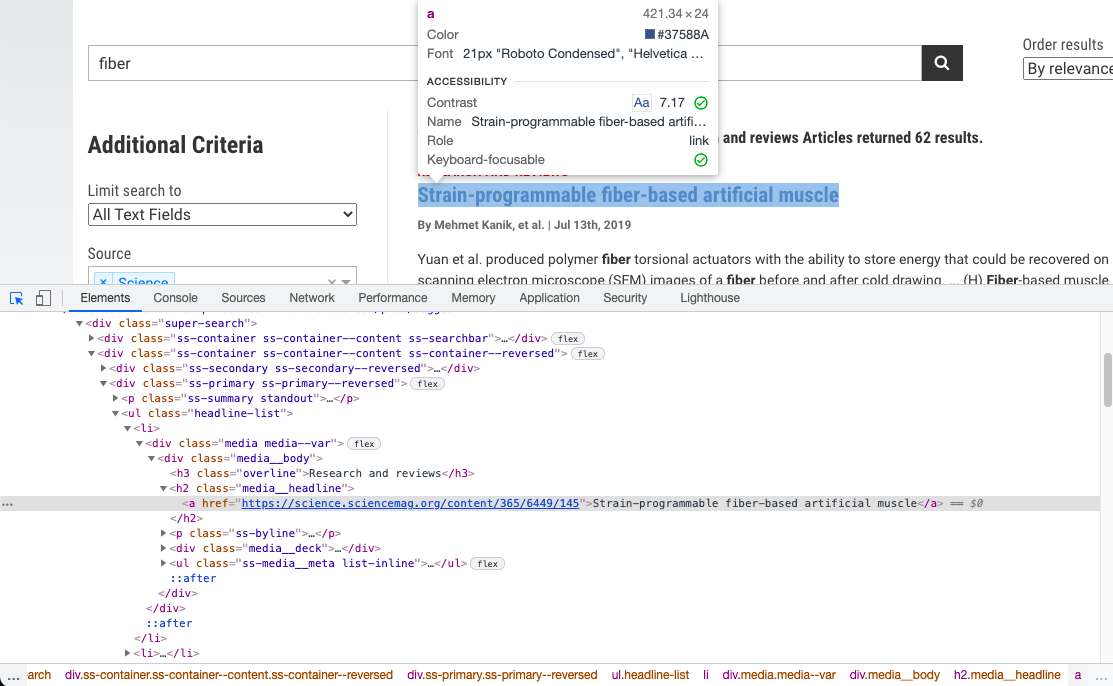
接着在HTML代码中鼠标右击选择复制xpath就可以得到该元素的xpath:
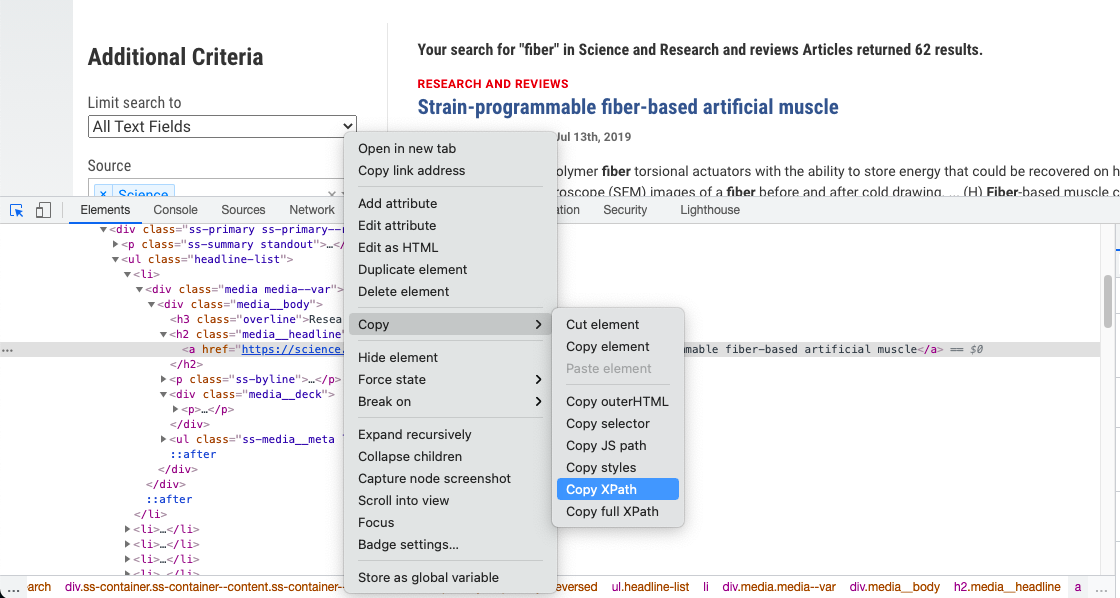
通过观察得到的xpath可以发现,所有的论文连接都在一个列表元素中,可以通过改变列表的序号li[i]来按顺序得到论文链接。如果希望得到第一个论文的链接,将i设为1。得到这个链接的元素后,使用curElem.click()即可以模拟鼠标点击这个元素,可以发现浏览器进入链接后的页面。
i = 1
cur_xpath = f'//*[@id="super-search-wrapper"]/div/div[2]/div[2]/ul/li[{i}]/div/div/h2/a'
curElem = driver.find_element_by_xpath(cur_xpath)
curElem.click()
使用 Selenium 控制浏览器窗口
浏览器实际工作中会使用到多个窗口,并在窗口之间切换。driver.switch_to_window()方法可以帮助你切换当前活动窗口。首先你可以当前的窗口列表:
print(driver.window_handles)
你可以使用下面的方法在不同的window之间切换,switch_to_frame是同样的道理:
driver.switch_to_window('window_name')
driver.switch_to.window(driver.window_handles[1])
如果处理完了相关的操作,希望回到主要的窗口,可以使用:
driver.switch_to_default_content()
回到论文链接抓取的任务,我们可以先通过send_keys()打开在新标签页中打开论文页面,切换到新窗口后,找到相关pdf的url,使用driver.close()关闭窗口,并切换到原来的窗口。
from selenium.webdriver.common.keys import Keys
for i in range(10):
cur_xpath = f'//*[@id="super-search-wrapper"]/div/div[2]/div[2]/ul/li[{i}]/div/div/h2/a'
curElem = driver.find_element_by_xpath(cur_xpath)
# 在新窗口中打开网页
curElem.send_keys(Keys.COMMAND + Keys.RETURN)
# 切换到第2个窗口
driver.switch_to.window(driver.window_handles[1])
# 点击 pdf 按钮
pdf_button_xpath = '//*[@id="block-system-main"]/div/div/article/div[2]/ul/li[5]/a[1]'
pdf_button = driver.find_element_by_xpath(pdf_button_xpath)
pdf_button.click()
# 找寻pdf的url
pdf_url_xpath = '//*[@id="panels-ajax-tab-container-highwire_article_tabs"]/div[3]/div/div/div/div/div[1]/div/p/a'
pdf_url = driver.find_element_by_xpath(pdf_url_xpath)
print(pdf_url.get_property('href'))
# 关闭窗口
driver.close()
# 切换到第一个窗口
driver.switch_to.window(driver.window_handles[0])
# 退出浏览器
driver.quit()
设置等待时间
在浏览器上加载页面的时候,一些single-page application需要你等一段时间才会开始有反应。为了模拟这样的等待时间,selenium 有两种类型的等待方式,explicit wait 和 implicit wait。explicit wait 需要等待特定的动作完成,比如ajax的内容加载;implicit wait 需要等待指定的时间。
一个 explicit wait 的模版如下,你可以使用try语法来处理过程中的异常,设置driver在等待一个元素的出现至固定的时间后再继续下一步:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
try:
element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.ID, "id-of-new-element"))
)
finally:
driver.quit()
WebDriverWait() 告诉 driver 等待事件发生直到5秒,presence_of_element_located()表示侦测到某个元素的出现。
implicit wait 等待固定的时间的语法为:
driver.implicitly_wait(5)
element = driver.find_element_by_id("id-of-new-element")
因此可以将上一节的抓取论文链接的代码改成再发现pdf的url后就关闭页面,所有的论文链接会被存储在pdf_url_lst当中。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
pdf_url_lst = []
delay = 3 # seconds
for i in range(1, 20):
cur_xpath = f'//*[@id="super-search-wrapper"]/div/div[2]/div[2]/ul/li[{i}]/div/div/h2/a'
try:
curElem = WebDriverWait(driver, delay).until(EC.presence_of_element_located((By.XPATH, cur_xpath)))
print(f"Page {i} is ready!")
except TimeoutException:
print("Loading took too much time!")
#curElem.click()
curElem.send_keys(Keys.COMMAND + Keys.RETURN)
# Switch tab to the new tab, which we will assume is the next one on the right
driver.switch_to.window(driver.window_handles[1])
pdf_button_xpath = '//*[@id="block-system-main"]/div/div/article/div[2]/ul/li[5]/a[1]'
try:
pdf_button = WebDriverWait(driver, delay).until(EC.presence_of_element_located((By.XPATH, pdf_button_xpath)))
except TimeoutException:
print("Loading took too much time!")
pdf_button.click()
pdf_url_xpath = '//*[@id="panels-ajax-tab-container-highwire_article_tabs"]/div[3]/div/div/div/div/div[1]/div/p/a'
try:
pdf_url = WebDriverWait(driver, delay).until(EC.presence_of_element_located((By.XPATH, pdf_url_xpath)))
except TimeoutException:
print("Loading took too much time!")
pdf_url_lst.append(pdf_url.get_property('href'))
asyncio.run(run('wget {}'.format(pdf_url.get_property('href'))))
# Close current tab
driver.close()
# Switch to main tab
driver.switch_to.window(driver.window_handles[0])
driver.quit()