Pytorch 使用多GPU进行训练
使用多块GPU来同时训练可以解决单块GPU训练时候出现的显存不足或者训练时间过长问题。本篇博客会介绍如何使用Pytorch的DataParalle模块来进行单机器多GPU训练,使用DistributedDataParallel进行更快速的单机器多GPU训练,多机器多GPU训练,使用launch script来执行多GPU训练任务。
简介
单块GPU在面对复杂的深度学习模型时会出现显存容量不足或者计算时间过长的问题,使用多块GPU来同时训练是解决这些问题的有效方法之一。Pytorch提供了不同的软件包来实现实现多块GPU来训练,这些软件包可以按照由简单到复杂的规律如下列出,开发者可以根据开发任务和开发阶段进行选择使用:
- 在单个GPU的情况下,数据和模型都容纳在一个GPU,这适合应用的原型开发
- 如果一个机器有多个GPU,你希望使用最少的代码改动来启用多GPU来加速训练或者扩大显存,可以使用DataParallel
- 如果希望进一步提高训练速度并且不介意再多写点代码,可以使用DistributedDataParallel
- 如果你希望使用到多台机器,可以使用DistributedDataParallel 和 launching script
- 如果希望能够在分布式训练的时候处理错误或者在训练时候计算资源能够动态的加入或者离开,可以使用torchelastic
- 如果训练时候发现先有软件包的范式不能满足要求,比如希望使用parameter server范式,distributed pipeline 范式,reinforcement learning applications with multiple observers or agents等,可以使用 torch.distributed.rpc 来开发以满足要求。
torch.nn.DataParallel
DataParallel包运行开能够使用一行代码就能够实现一台机器上的多GPU训练:
model = nn.DataParallel(model)
可以参考Optional: Data Parallelism来查看使用DataParallel的完整代码。
尽管代码需要改动的地方少,使用DataParallel在运行效率考虑却不是最好的选择。这时因为DataParallel的实现方法中在每一次模型的前向传播都会复制一次模型,同时它使用single-process multi-thread并行,所以会受到GIL的限制。如果希望取得更好的性能表现,应该使用DistributedDataParallel。
torch.nn.parallel.DistributedDataParallel
在使用DistributedDataParallel的时候,需要先设置init_process_group。DDP使用 multi-process 并行,所以没有GIL的限制。同时模型实在DDP构建的时候传播到每个进程而不是每次传播的时候复制,这也能够加速训练。DDP还有其它优化技术,具体可以查看DDP paper。
基本原理
要想创建DDP模型,首先要正确设置process groups。pytorch的DistributedDataParallel(DDP)模块需要指定构建好的深度学习网络模型module类,DDP会把模型和其中的状态传播到rank0到N不同的进程中。DDP算法的构建,前向传播,反向传播是重要的步骤。前向传播会把数据划分喂入到不同的进程当中,反向传播时候会收集不同进程的梯度,然后进行reduce,最后把每个进程中的模型状态根据梯度进行更新。
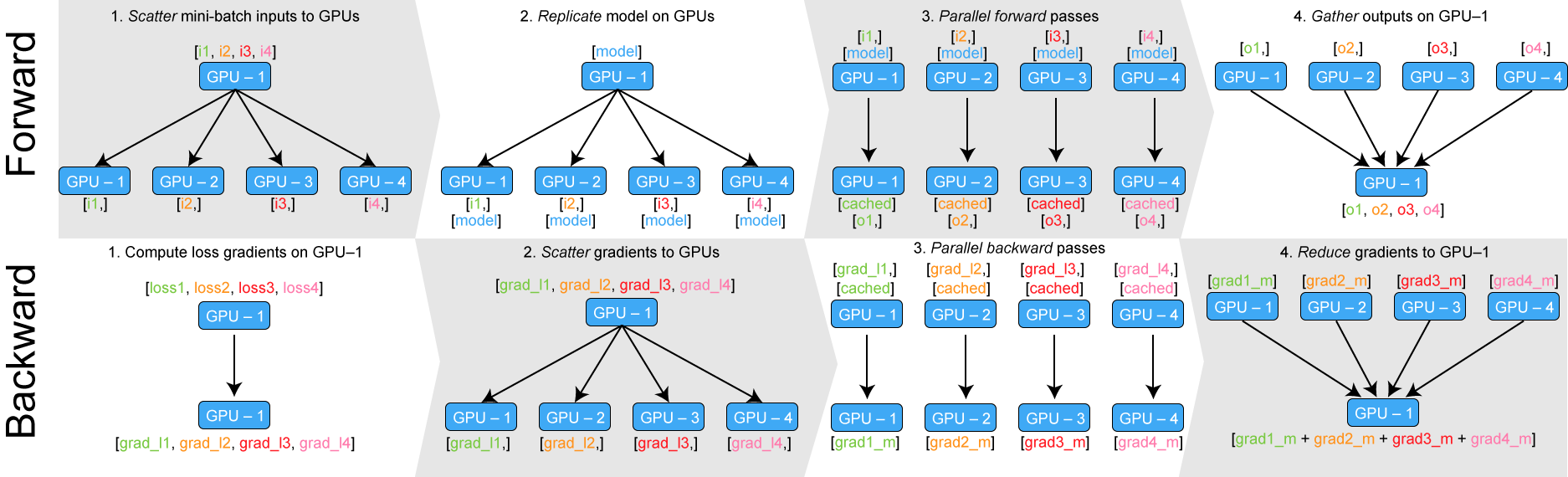
DDP在构建阶段就会完成初始化模型的状态,你不需要担心每个进程包含不同的初始状态。
DDP module已经把底层的分布式通信细节隐藏了起来,只暴露了类似于单一本地模型的API。
使用DDP的时候,模型会被先save到一个进程,然后加载到所有的进程。所以需要注意所有进程要在模型save完成之后在load。同时在保存的时候,指定一个rank进行就足够了,在load的时候,需要指定map_location来防止访问到其它设备。
DDP还支持多GPU的模型,即一个模型不同步骤使用不同GPU来计算,这对于非常大的模型计算大量数据会有用。
测试能否使用DDP
import os
import torch.distributed as dist
print(f"[ {os.getpid()} ] Initializing process group")
dist.init_process_group(backend="nccl")
print(f"[ {os.getpid()} ] world_size = {dist.get_world_size()}, " + f"rank = {dist.get_rank()}, backend={dist.get_backend()}")
上面的代码可以用来检查在一台机器或者多台机器能否正常启动process group。它首先使用init_process_group()函数启动了process group,然后打印出进程号和world_size。如果你只在一台多GPU机器上运行,需要使用launch script执行程序:
python -m torch.distributed.launch --nnodes 1 init_proc.py
如果要在多台机器上运行程序,那么分别在每个机器上运行脚本:
# first machine
python -m torch.distributed.launch --nnodes 2 --nproc_per_node 2 --node_rank 0 --master_addr="1.2.3.4" --master_port=29500 init_proc.py
# second machine
python -m torch.distributed.launch --nnodes 2 --nproc_per_node 2 --node_rank 1 --master_addr="1.2.3.4" --master_port=29500 init_proc.py
其中nnodes为机器数量,nproc_per_node等于每台机器GPU数量,node_rank为每台机器的序号,从0到N-1。程序执行成功后,可以在每台机器上看到类似下面的输出结果。
[ 1329560 ] Initializing process group
[ 1329560 ] world_size = 4, rank = 0, backend=nccl
使用DDP spawn的例子
如果希望了解DDP spawn的使用方法,可以结合下面的代码并这里进行参考。
import os
import tempfile
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
def demo_checkpoint(rank, world_size):
print(f"Running DDP checkpoint example on rank {rank}.")
setup(rank, world_size)
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
# All processes should see same parameters as they all start from same
# random parameters and gradients are synchronized in backward passes.
# Therefore, saving it in one process is sufficient.
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# Use a barrier() to make sure that process 1 loads the model after process
# 0 saves it.
dist.barrier()
# configure map_location properly
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
optimizer.step()
# Use a barrier() to make sure that all processes have finished reading the
# checkpoint
dist.barrier()
if rank == 0:
os.remove(CHECKPOINT_PATH)
cleanup()
class ToyMpModel(nn.Module):
def __init__(self, dev0, dev1):
super(ToyMpModel, self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
def demo_model_parallel(rank, world_size):
print(f"Running DDP with model parallel example on rank {rank}.")
setup(rank, world_size)
# setup mp_model and devices for this process
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad()
# outputs will be on dev1
outputs = ddp_mp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(dev1)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
if n_gpus < 2:
print(f"Requires at least 8 GPUs to run, but got {n_gpus}.")
else:
run_demo(demo_basic, 2)
run_demo(demo_checkpoint, 2)
run_demo(demo_model_parallel, 1)
使用launch script
DDP可以使用spawn函数孵化出多个进程来进行多GPU训练要求训练的函数必须能够被pickle压缩。而使用launch script却没有这个限制,因此使用得更加广泛。
- 使用
launch脚本需要保留--local_rank命令行参数 - 使用
DistributedDataParallel包裹模型 - 使用
DistributedSampler用于dataloader - 下载数据集或者创建文件夹这样的操作在分布式程序中是不安全的,如果一定要使用,可以考虑
torch.distributed.barrier
上节的代码可以改写成:
import argparse
import os
import sys
import tempfile
from urllib.parse import urlparse
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(local_world_size, local_rank):
# setup devices for this process. For local_world_size = 2, num_gpus = 8,
# rank 0 uses GPUs [0, 1, 2, 3] and
# rank 1 uses GPUs [4, 5, 6, 7].
n = torch.cuda.device_count() // local_world_size
device_ids = list(range(local_rank * n, (local_rank + 1) * n))
print(
f"[{os.getpid()}] rank = {dist.get_rank()}, "
+ f"world_size = {dist.get_world_size()}, n = {n}, device_ids = {device_ids} \n", end=''
)
model = ToyModel().cuda(device_ids[0])
ddp_model = DDP(model, device_ids)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_ids[0])
loss_fn(outputs, labels).backward()
optimizer.step()
def spmd_main(local_world_size, local_rank):
# These are the parameters used to initialize the process group
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "RANK", "WORLD_SIZE")
}
if sys.platform == "win32":
# Distributed package only covers collective communications with Gloo
# backend and FileStore on Windows platform. Set init_method parameter
# in init_process_group to a local file.
if "INIT_METHOD" in os.environ.keys():
print(f"init_method is {os.environ['INIT_METHOD']}")
url_obj = urlparse(os.environ["INIT_METHOD"])
if url_obj.scheme.lower() != "file":
raise ValueError("Windows only supports FileStore")
else:
init_method = os.environ["INIT_METHOD"]
else:
# It is a example application, For convience, we create a file in temp dir.
temp_dir = tempfile.gettempdir()
init_method = f"file:///{os.path.join(temp_dir, 'ddp_example')}"
dist.init_process_group(backend="gloo", init_method=init_method, rank=int(env_dict["RANK"]), world_size=int(env_dict["WORLD_SIZE"]))
else:
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
print(
f"[{os.getpid()}]: world_size = {dist.get_world_size()}, "
+ f"rank = {dist.get_rank()}, backend={dist.get_backend()} \n", end=''
)
demo_basic(local_world_size, local_rank)
# Tear down the process group
dist.destroy_process_group()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# This is passed in via launch.py
parser.add_argument("--local_rank", type=int, default=0)
# This needs to be explicitly passed in
parser.add_argument("--local_world_size", type=int, default=1)
args = parser.parse_args()
# The main entry point is called directly without using subprocess
spmd_main(args.local_world_size, args.local_rank)
运行程序的命令为:
python /path/to/launch.py --nnode=1 --node_rank=0 --nproc_per_node=8 example.py --local_world_size=8
python /path/to/launch.py --nnode=1 --node_rank=0 --nproc_per_node=1 example.py --local_world_size=1
一个DDP实际使用例子
下面的代码演示了如何使用torch.distributed.launch来分布式训练CIFAR-10分类任务:
import torch
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
import os
import random
import numpy as np
def set_random_seeds(random_seed=0):
torch.manual_seed(random_seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
def evaluate(model, device, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
return accuracy
def main():
num_epochs_default = 10000
batch_size_default = 256 # 1024
learning_rate_default = 0.1
random_seed_default = 0
model_dir_default = "saved_models"
model_filename_default = "resnet_distributed.pth"
# Each process runs on 1 GPU device specified by the local_rank argument.
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--local_rank", type=int, help="Local rank. Necessary for using the torch.distributed.launch utility.")
parser.add_argument("--num_epochs", type=int, help="Number of training epochs.", default=num_epochs_default)
parser.add_argument("--batch_size", type=int, help="Training batch size for one process.", default=batch_size_default)
parser.add_argument("--learning_rate", type=float, help="Learning rate.", default=learning_rate_default)
parser.add_argument("--random_seed", type=int, help="Random seed.", default=random_seed_default)
parser.add_argument("--model_dir", type=str, help="Directory for saving models.", default=model_dir_default)
parser.add_argument("--model_filename", type=str, help="Model filename.", default=model_filename_default)
parser.add_argument("--resume", action="store_true", help="Resume training from saved checkpoint.")
argv = parser.parse_args()
local_rank = argv.local_rank
num_epochs = argv.num_epochs
batch_size = argv.batch_size
learning_rate = argv.learning_rate
random_seed = argv.random_seed
model_dir = argv.model_dir
model_filename = argv.model_filename
resume = argv.resume
# Create directories outside the PyTorch program
# Do not create directory here because it is not multiprocess safe
'''
if not os.path.exists(model_dir):
os.makedirs(model_dir)
'''
model_filepath = os.path.join(model_dir, model_filename)
# We need to use seeds to make sure that the models initialized in different processes are the same
set_random_seeds(random_seed=random_seed)
# Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.distributed.init_process_group(backend="nccl")
# torch.distributed.init_process_group(backend="gloo")
# Encapsulate the model on the GPU assigned to the current process
model = torchvision.models.resnet18(pretrained=False)
device = torch.device("cuda:{}".format(local_rank))
model = model.to(device)
ddp_model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
# We only save the model who uses device "cuda:0"
# To resume, the device for the saved model would also be "cuda:0"
if resume == True:
map_location = {"cuda:0": "cuda:{}".format(local_rank)}
ddp_model.load_state_dict(torch.load(model_filepath, map_location=map_location))
# Prepare dataset and dataloader
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# Data should be prefetched
# Download should be set to be False, because it is not multiprocess safe
train_set = torchvision.datasets.CIFAR10(root="data", train=True, download=False, transform=transform)
test_set = torchvision.datasets.CIFAR10(root="data", train=False, download=False, transform=transform)
# Restricts data loading to a subset of the dataset exclusive to the current process
train_sampler = DistributedSampler(dataset=train_set)
train_loader = DataLoader(dataset=train_set, batch_size=batch_size, sampler=train_sampler, num_workers=8)
# Test loader does not have to follow distributed sampling strategy
test_loader = DataLoader(dataset=test_set, batch_size=128, shuffle=False, num_workers=8)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-5)
# Loop over the dataset multiple times
for epoch in range(num_epochs):
print("Local Rank: {}, Epoch: {}, Training ...".format(local_rank, epoch))
# Save and evaluate model routinely
if epoch % 10 == 0:
if local_rank == 0:
accuracy = evaluate(model=ddp_model, device=device, test_loader=test_loader)
torch.save(ddp_model.state_dict(), model_filepath)
print("-" * 75)
print("Epoch: {}, Accuracy: {}".format(epoch, accuracy))
print("-" * 75)
ddp_model.train()
for data in train_loader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = ddp_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if __name__ == "__main__":
main()
在第一个机器上运行:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --node_rank=0 --master_addr="192.168.0.1" --master_port=1234 resnet_ddp.py
在第二个机器上运行:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --node_rank=1 --master_addr="192.168.0.1" --master_port=1234 resnet_ddp.py
常见问题
- 确认机器安装的pytorch版本一样,最好都是最近的版本,我试过pytorch1.7和pytorch1.8之间是不能通信的
- 确认每个机器上的防火墙已经打开,可以使用telnel来检查另一台机器的端口是否能够连通,你可以参考init_process_group with launch.py –nnode=2 hangs always in all machines · Issue #52848 · pytorch/pytorch (github.com)来debug机器的网络
单机器多GPU训练
python -m torch.distributed.launch --nproc_per_node=4
--nnodes=1 --node_rank=0
--master_port=1234 train.py <OTHER TRAINING ARGS>
结束训练
kill $(ps aux | grep resnet_ddp.py | grep -v grep | awk '{print $2}')
参考
- PyTorch Distributed Overview — PyTorch Tutorials 1.9.0+cu102 documentation
- examples/distributed/ddp at master · pytorch/examples (github.com)
- Lei Mao’s Log Book – PyTorch Distributed Training
- Invited Talk: PyTorch Distributed (DDP, RPC) - By Facebook Research Scientist Shen Li - YouTube
- examples/main.py at master · pytorch/examples (github.com)
-
[💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups by Thomas Wolf HuggingFace Medium](https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255) -
[Distributed Neural Network Training In Pytorch by Nilesh Vijayrania Towards Data Science](https://towardsdatascience.com/distributed-neural-network-training-in-pytorch-5e766e2a9e62)